

 ケケンタ
ケケンタPHPでスクレイピングしてみたいんだけど、やり方がわからない……
このようなお悩みをお持ちの方に向けて、この記事では
PHPでスクレイピングする方法
を解説します。
- PHPのライブラリパッケージを使用してスクレイピングする方法
- スクレイピングの実践的なソースコード
PHPではパッケージを使用しなくても比較的簡単にスクレイピングする方法が用意されています。
しかし、その方法では最低限のことしか実装できないため、当記事では応用のしやすも重視する意味で、パッケージでスクレイピングする方法をご紹介します。
 ケケンタ
ケケンタスクレイピングが初めての方やPHPを触り始めたばかりの方にとっては難しく感じる部分もあるかと思いますが、まずは当記事のソースコードを丸々コピペして動作を確認するだけでも勉強になるかと思います。
Webアプリ開発に興味がある方におすすめの記事

Webアニメーションの引き出しを増やしたい人におすすめの書籍


もしプログラミング学習やお仕事で運動不足が気になっているなら
連続屈伸運動がおすすめです!
ボタンにカーソルを合わせるだけで
カウントダウンが始まるタイマーをご用意してみました!
ケケンタ無理のない範囲で、ぜひ隙間時間に屈伸運動を取り入れてみて下さい!
タイマースタート
3:00

スクレイピングの前提知識
【その①】スクレイピングの仕組み
スクレイピングの大まかな流れは以下の通りです。
- 欲しい情報が掲載されているページのドキュメントをダウンロードする
- ダウンロードしたドキュメントをパース(構文解析)する=どの情報がどの場所にあるのかを特定する
- パースしたドキュメントから欲しい情報を抜き出す
今回はこの内、①と②をパッケージで対応します。
③についてはPHPの基本機能で実装可能です。
【その②】使用するパッケージ
今回のスクレイピングでは、以下の2つのパッケージを使用します。
- Guzzle
- PHP DOM Wrapper
Guzzleとは?
PHPのHTTPクライアントのパッケージです。
今回はURLを指定して、そのページのドキュメントをダウンロードするために使用します。
PHP DOM Wrapperとは?
Webページのドキュメントをパース(構文解析)できるパッケージです。
今回はGuzzleでダウンロードしたドキュメントをパースするために使用します。
【その③】スクレイピングを行う際の注意点
スクレイピングはプログラムによってWebサイトの情報を自動で抽出する技術です。
そのため、人が手動でサイトへアクセスするのとは比にならない速度で処理が進みます。
何も対策をしないと、最悪スクレイピング対象のサイトのサーバーが過負荷に耐えられずに落ちてしまい、運営者から法的処置を取られてしまう可能性もあります。
ケケンタスクレイピングを本番サイト上で実施する際には主に以下の点に注意しましょう!
- 対象のサイトに過剰な負荷をかけないように、情報取得処理の間に待機時間を設ける
- スクレイピングが禁止されているサイトでは行わない
- プログラムの不具合によりアクセス先のサイトに過剰な負荷をかけないよう、ローカル環境でのテストやデバッグを徹底する
【事前準備】Composerでパッケージをインストールする
それでは、ここから実際にスクレイピング機能を実装するための作業を進めていきます。
まずは今回のスクレイピングで利用する以下のパッケージをインストールしていきます。
- Guzzle
- PHP DOM Wrapper
ケケンタパッケージのインストールにはComposerを使用します。
「Composerってなに?」という方やまだインストールしていないという方は以下の記事をご覧ください。
パッケージのインストール手順
- スクレイピング実装用のプロジェクトディレクトリを作成する
- 作成したプロジェクトディレクトリ内に
composer.jsonファイルを作成する composer.jsonファイル内にパッケージインストール用の記述をする
まずはいつもPHPでアプリを作成するときと同様に、プロジェクトディレクトリを作成します。
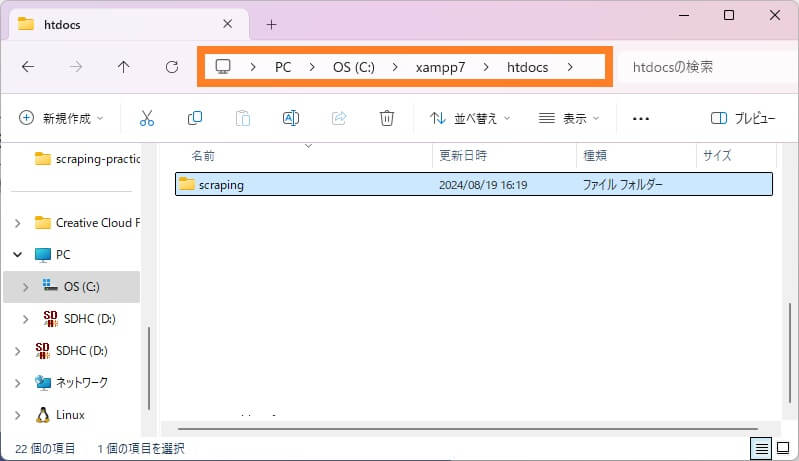
続いて、作成したプロジェクトディレクトリ内にcomposer.jsonファイルを作成します。
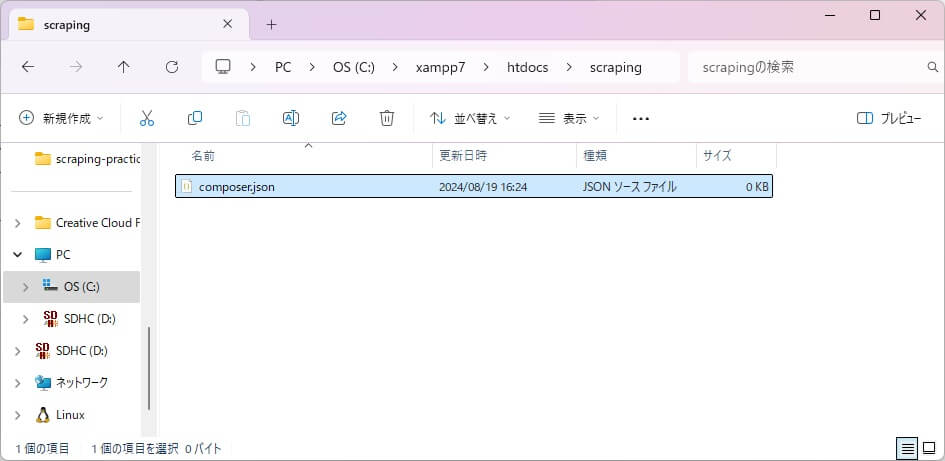
普段お使いのテキストエディタでcomposer.jsonファイルを開き、下記を記述します。
{
"require": {
"guzzlehttp/guzzle": "*",
"scotteh/php-dom-wrapper": "*"
}
}バージョンに「*」を指定することで最新バージョンがインストールされます。
プロジェクトディレクトリ上でターミナルを開きます。
Windows11の場合
プロジェクトディレクトリ内で「右クリック」→「ターミナルで開く」をクリック
Windows10の場合
プロジェクトディレクトリ内で「Shift + 右クリック」→「ターミナルで開く」をクリック
(※「ターミナルで開く」が無ければ「コマンドプロンプト」でもOK)
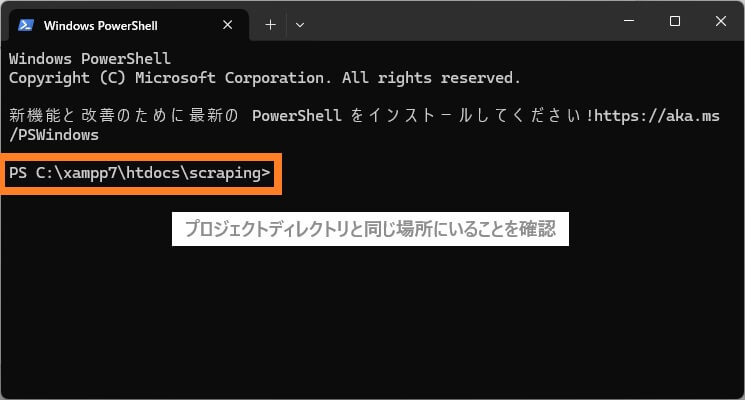
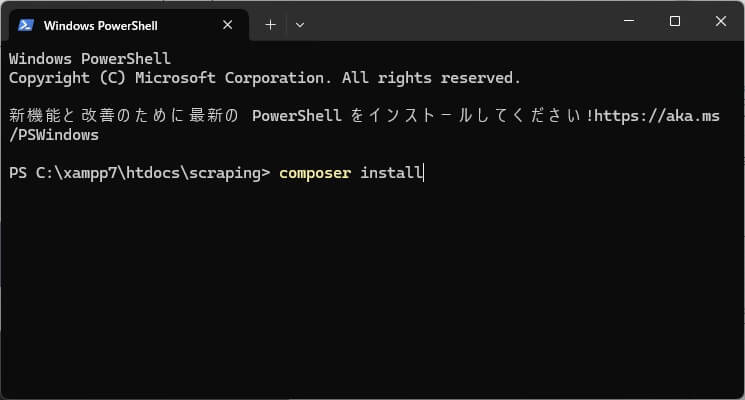
プロジェクトディレクトリ上でターミナルを開いたらcomposer installコマンドを実行します。
 ケケンタ
ケケンタ以上で今回使用する2つのパッケージのインストールが完了しました!
このあとの章からは、実際にこれらのパッケージをファイル内に読み込んでスクレイピングを行っていきます。
【基本】PHPでスクレイピングをする
トップ画面
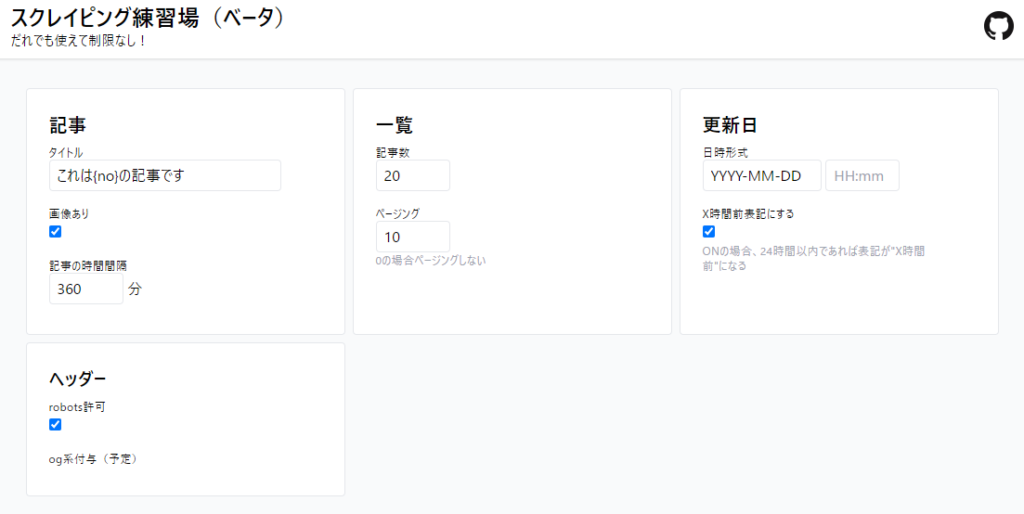
今回作成するスクレイピングを実行するための基本的なソースコードは以下のとおりです。
※scrap.phpというファイルを新規に作成しています。
【ソースコード】スクレイピングを実行する
<?php
// Composerでインストールしたパッケージを読み込む
require_once __DIR__ . '/vendor/autoload.php';
use DOMWrap\Document;
use GuzzleHttp\Client;
// スクレイピング対象のURL
$url = 'https://scraping-training.vercel.app/site?postCount=20&title=%E3%81%93%E3%82%8C%E3%81%AF{no}%E3%81%AE%E8%A8%98%E4%BA%8B%E3%81%A7%E3%81%99&dateFormat=YYYY-MM-DD&isTime=true&timeFormat=&isImage=true&interval=360&isAgo=true&countPerPage=2&page=1&robots=true&';
// URLを元にページ内のHTML構造を取得
$client = new Client;
$response = $client->get( $url );
$html = (string) $response->getBody();
$doc = new Document;
$node = $doc->html( $html );
// スクレイピングを実行
// 1つ目の記事の「タイトル」と「投稿日時」を取得
$title = $node->find( 'article:nth-child(1) .post-title' )->text();
$post_date = $node->find( 'article:nth-child(1) time' )->text();
// スクレイピングした情報を出力
echo '投稿タイトル:' . $title . '<br />';
echo '投稿日時:' . $post_date;
?>以下よりソースコードの解説をしていきます!
解説
① パッケージを読み込む
// Composerでインストールしたパッケージを読み込む
require_once __DIR__ . '/vendor/autoload.php';ここではComposerの機能のひとつ「オートロード」を利用しています。
本来ならパッケージごとにrequireを記述する必要がありますが、「オートロード」を利用することで、上記の1行だけでComposerでインストールしたパッケージをファイルへ読み込むことが可能です。
② パッケージのクラスを使用できるようにする
use DOMWrap\Document;
use GuzzleHttp\Client;③ スクレイピングしたいページのURLを記述
// スクレイピング対象のURL
$url = 'https:// ~省略~ ';④ URL先のドキュメントをダウンロード → パース(構文解析)
// URLを元にページ内のHTML構造を取得
$client = new Client;
$response = $client->get( $url );
$html = (string) $response->getBody();
$doc = new Document;
$node = $doc->html( $html );⑤ CSSセレクターを指定することで欲しい情報を取得
// スクレイピングを実行
// 1つ目の記事の「タイトル」と「投稿日時」を取得
$title = $node->find( 'article:nth-child(1) .post-title' )->text();
$post_date = $node->find( 'article:nth-child(1) time' )->text(); ※今回は例として「1ページにある1つ目の記事の『タイトル』と『投稿日時』」を取得しています。
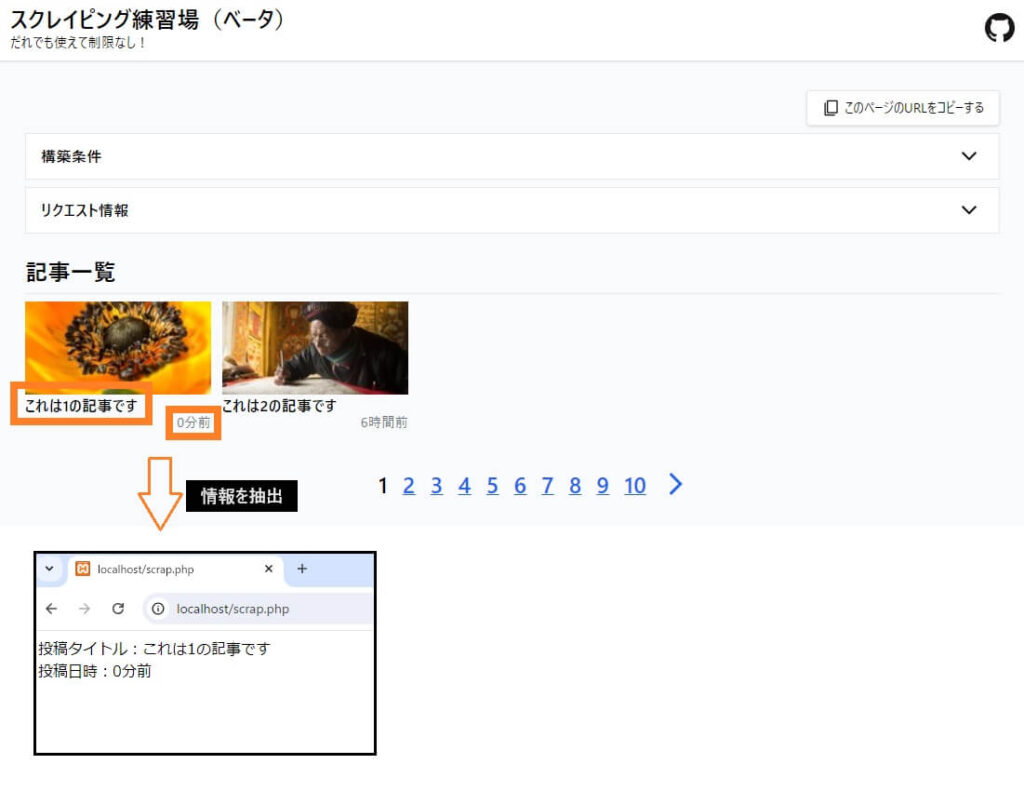
CSSセレクターの確認方法がご不明な方におすすめの記事

⑥ スクレイピングした情報をブラウザに出力
// スクレイピングした情報を出力
echo '投稿タイトル:' . $title . '<br />';
echo '投稿日時:' . $post_date;以上がスクレイピングのもっとも基本的なソースコードです!
これをベースとし、あとは
- すべてのページの全記事の情報を取得する
- 取得した情報をデータベースへ保存する
などの実装ができれば、スクレイピングの基礎は身につけたと言えるのではないでしょうか。
【発展編】スクレイピングの基本コードをベースに実践的な実装に挑戦!
ここからはスクレイピングの基本的なソースコードを改変した、より発展的なソースコードをご紹介します。
ケケンタおおよその流れはお伝えしますが、細かい部分についてはあえて解説を割愛させていただきます。
まずはぜひご自身で実装に挑戦していただき、その答え合わせとしてご活用していただければと思います!
【発展①】サイト内すべての記事情報をスクレイピングする
- 全ページ数を取得する必要がある
- 各ページ内の記事数を取得する必要がある
- 記事の並び順に合わせたCSSセレクターを指定する必要がある
- ページ番号が変わる=URLが変わる(どんな法則で変わるのか?を知り、その性質を利用する)
- (本番サイトを想定して)スクレイピングの実行間隔をあける
<?php
require_once __DIR__ . '/vendor/autoload.php';
use DOMWrap\Document;
use GuzzleHttp\Client;
// 最後のページ番号
$last_page_num = getLastPageNum();
$client = new Client;
// ページごとの記事情報をスクレイピング
for( $i=1; $i<=$last_page_num; $i++ ){
// スクレイピング対象のURL
$url = 'https://scraping-training.vercel.app/site?postCount=20&title=%E3%81%93%E3%82%8C%E3%81%AF{no}%E3%81%AE%E8%A8%98%E4%BA%8B%E3%81%A7%E3%81%99&dateFormat=YYYY-MM-DD&isTime=true&timeFormat=&isImage=true&interval=360&isAgo=true&countPerPage=2&page='. $i .'&robots=true&';
// URLを元にページ内のHTML構造を取得
$response = $client->get( $url );
$html = (string) $response->getBody();
$doc = new Document;
$node = $doc->html( $html );
// ページ内の記事数
$article_num = getArticleNum( $node );
// セレクター
$selectors = setSelectors( $article_num );
// スクレイピングを実行
// 現在のページ内の記事の「タイトル」と「投稿日時」を取得
foreach( $selectors as $selector ){
$title = $node->find( $selector['title'] )->text();
$post_date = $node->find( $selector['post_date'] )->text();
// スクレイピングした情報を出力
echo '投稿タイトル:' . $title . '<br />';
echo '投稿日時:' . $post_date . '<br />';
echo '-----------------<br />';
// 待機時間
sleep(3);
}
}
/***********************************/
/* 関数定義 */
/***********************************/
/**
* 最後のページを取得する
*/
function getLastPageNum()
{
$client = new Client;
// 取得情報
$url = 'https://scraping-training.vercel.app/site?postCount=20&title=%E3%81%93%E3%82%8C%E3%81%AF{no}%E3%81%AE%E8%A8%98%E4%BA%8B%E3%81%A7%E3%81%99&dateFormat=YYYY-MM-DD&isTime=true&timeFormat=&isImage=true&interval=360&isAgo=true&countPerPage=2&page=1&robots=true&';
// セレクター
$last_page_selector = '.pagination > a:nth-last-child(2) > span';
// レスポンス
$response = $client->get( $url );
$html = (string) $response->getBody();
$doc = new Document;
$node = $doc->html( $html );
// 取得情報
$last_page_num = $node->find( $last_page_selector )->text();
return $last_page_num;
}
/**
* ページ内の記事数を取得
*/
function getArticleNum( $doc )
{
$article_node = $doc->find( 'article' );
return $article_node->count();
}
/**
* ページ内の記事情報を取得するためのセレクターをセット
*/
function setSelectors( $article_num )
{
$selectors = array();
for( $j=1; $j<=$article_num; $j++ ){
$selectors[] = [
'title' => 'article:nth-child(' . $j . ') .post-title',
'post_date' => 'article:nth-child(' . $j . ') time',
];
}
return $selectors;
}
/***********************************/
?>
【発展②】スクレイピングした情報をデータベースに保存する
この【発展②】は、【発展①】にデータベースへの保存機能を取り付けたものです。
そのため、まずは【発展①】の理屈をきちんと理解してから挑戦することをおすすめします。
<?php
require_once __DIR__ . '/vendor/autoload.php';
use DOMWrap\Document;
use GuzzleHttp\Client;
/**
* DB接続情報
*/
const DB_HOST = 'mysql:dbname=scraping;host=127.0.0.1;charset=utf8';
const DB_USER = 'kekenta';
const DB_PASSWORD = 'kekenta_pass';
/**
* 取得情報をデータベースに格納する
* データベース接続処理
*/
try {
$pdo = new PDO(DB_HOST, DB_USER, DB_PASSWORD, [
PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION,
PDO::ATTR_EMULATE_PREPARES => false,
]);
$sql = ('
INSERT INTO
scraping_practice01(title, post_date)
VALUES
(:TITLE, :POST_DATE)
');
$stmt = $pdo->prepare($sql);
} catch (PDOException $e) {
echo '接続失敗' . $e->getMessage();
exit();
}
// 最後のページ番号
$last_page_num = getLastPageNum();
$client = new Client;
for( $i=1; $i<=$last_page_num; $i++ ){
// スクレイピング対象のURL
$url = 'https://scraping-training.vercel.app/site?postCount=20&title=%E3%81%93%E3%82%8C%E3%81%AF{no}%E3%81%AE%E8%A8%98%E4%BA%8B%E3%81%A7%E3%81%99&dateFormat=YYYY-MM-DD&isTime=true&timeFormat=&isImage=true&interval=360&isAgo=true&countPerPage=2&page='. $i .'&robots=true&';
// URLを元にページ内のHTML構造を取得
$response = $client->get( $url );
$html = (string) $response->getBody();
$doc = new Document;
$node = $doc->html( $html );
// ページ内の記事数
$article_num = getArticleNum( $node );
// セレクター
$selectors = setSelectors( $article_num );
// スクレイピングを実行
// 現在のページ内の記事の「タイトル」と「投稿日時」を取得
foreach( $selectors as $selector ){
$title = $node->find( $selector['title'] )->text();
$post_date = $node->find( $selector['post_date'] )->text();
$post_date = changeTimeToToday($post_date);
// 取得情報をデータベースに格納する
$stmt->bindValue(':TITLE' , $title , PDO::PARAM_STR);
$stmt->bindValue(':POST_DATE', $post_date, PDO::PARAM_STR);
$stmt->execute();
// 待機時間
sleep(3);
}
}
// DBとの接続を切る
$pdo = null;
$stmt = null;
/***********************************/
/* 関数定義 */
/***********************************/
/**
* 最後のページを取得する
*/
function getLastPageNum()
{
$client = new Client;
// 取得情報
$url = 'https://scraping-training.vercel.app/site?postCount=20&title=%E3%81%93%E3%82%8C%E3%81%AF{no}%E3%81%AE%E8%A8%98%E4%BA%8B%E3%81%A7%E3%81%99&dateFormat=YYYY-MM-DD&isTime=true&timeFormat=&isImage=true&interval=360&isAgo=true&countPerPage=2&page=1&robots=true&';
// セレクター
$last_page_selector = '.pagination > a:nth-last-child(2) > span';
// レスポンス
$response = $client->get( $url );
$html = (string) $response->getBody();
$doc = new Document;
$node = $doc->html( $html );
// 取得情報
$last_page_num = $node->find( $last_page_selector )->text();
return $last_page_num;
}
/**
* ページ内の記事数を取得
*/
function getArticleNum( $doc )
{
$article_node = $doc->find( 'article' );
return $article_node->count();
}
/**
* ページ内の記事情報を取得するためのセレクターをセット
*/
function setSelectors( $article_num )
{
$selectors = array();
for( $j=1; $j<=$article_num; $j++ ){
$selectors[] = [
'title' => 'article:nth-child(' . $j . ') .post-title',
'post_date' => 'article:nth-child(' . $j . ') time',
];
}
return $selectors;
}
/**
* 今日の投稿なら$post_dateに「今日の日付」をセットする
*/
function changeTimeToToday( $post_date )
{
if( strpos($post_date,(string)'前') !== false ){
$post_date = date("Y-m-d");
}
return $post_date;
}
/***********************************/
?>
まとめ
いかがだったでしょうか。
PHPでスクレイピングをする方法はいくつかありますが、今回は2つのパッケージを組み合わせる方法を採用してみました。
- Guzzle
- PHP DOM Wrapper
スクレイピングをするための最低限のソースコードの型はほとんど決まっています。
しかし、サイトに合わせて自由に情報を取得するとなった場合、サイトの構造を理解し、それに合わせたソースコードを記述する必要があります。
スクレイピングを実装するのが難しいと感じるとしたら、大多数はこの部分に対してなのではないかと思います。
ケケンタスクレイピングに慣れるまでは、この記事でご紹介したスクレイピング練習場を利用するのもオススメです。
そうすれば、うっかりどこかのサイトへ過負荷をかけて迷惑をかけてしまう(最悪法的な処置を取られてしまう)ということもありません。
この記事をご参考に、ぜひPHPでスクレイピングに挑戦してみてください!

Webアプリ開発に興味がある方におすすめの記事






コメント